Artificial Intelligence
en Machine Learning
ontwikkelingen volgen elkaar snel op
AI-bouwstenen
Als je alleen veel blokjes van één type Lego hebt, kun je slechts eenvoudige bouwwerken maken. Maar met veel verschillende soorten blokjes kun je snel complexe, functionele structuren bouwen.
Zo werkt het ook met AI: alleen weten hoe je een LLM-API aanroept is een goed begin, maar beperkt. Met een breed arsenaal aan tools en technieken — zoals promptstrategieën, agent-frameworks, evaluaties, guardrails, retrieval (RAG), voice-technologie, asynchrone programmering, data-extractie, embeddings en vector databases, model fine-tuning, grafendatabases, agent-gebaseerde browser- of computerinteracties, MCP, reasoning-modellen, enzovoort — kun je veel krachtigere en geavanceerdere AI-oplossingen bouwen.
Wil je meer weten van de techniek achter AI? Hier vind je alle papers van de afgelopen tijd. Op YouTube wordt het enigszins begrijpelijk uitgelegd door Sebastian Raschka, Andrej Karpathy en bijvoorbeeld 3Blue1Brown.
Language models en Diffusion models
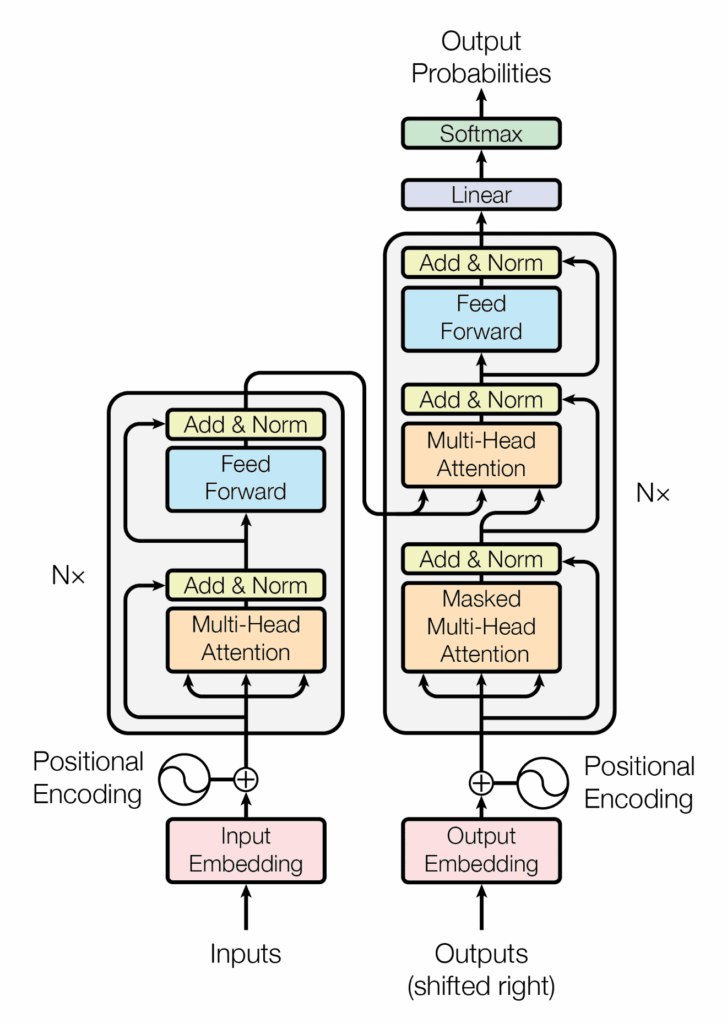
De opkomst van kunstmatige intelligentie heeft geleid tot indrukwekkende ontwikkelingen op het gebied van taalbegrip en beeldgeneratie. Twee van de meest invloedrijke technieken in deze gebieden zijn Large Language Models (LLMs of kort LMs) en Diffusion Models (DMs) – je hebt ook nog Generative Adversarial Networks (GAN), Variational Autoencoders (VAE) en Flow-based modellen. Hoewel allen gebruikmaken van geavanceerde wiskunde en deep learning, verschillen ze fundamenteel in hun doel en werking.
Language Models (taalmodellen): De evolutie van begrip en generatie
Language Models zijn ontworpen om menselijke taal te begrijpen en te genereren. De geschiedenis begint bij vroege probabilistische modellen, zoals n-grams, die woorden voorspellen op basis van statistische waarschijnlijkheden. In de vroege jaren 2000 introduceerde men neurale netwerken, zoals word embeddings (Word2Vec, GloVe), die woorden in een continue vectorruimte plaatsen en zo semantische relaties vastleggen.
De echte doorbraak kwam met Transformer-gebaseerde modellen, geïntroduceerd door Vaswani et al. in 2017. Het revolutionaire model BERT (2018) van Google verbeterde begrip door context uit beide richtingen van een zin te halen. Daarna bracht OpenAI GPT-modellen (Generative Pre-trained Transformer) uit, die niet alleen tekst begrijpen maar ook vloeiend genereren. GPT-3 (2020) en GPT-4 (2023) toonden aan hoe krachtig zulke modellen konden zijn, met toepassingen in vertalingen, chatbots en codegeneratie.
Diffusion Models (diffusie modellen): De evolutie van beeldgeneratie
Diffusion Models zijn een recente innovatie op het gebied van beeldgeneratie. De oorsprong ligt bij Generative Adversarial Networks (GANs) en Variational Autoencoders (VAEs), maar deze hadden beperkingen zoals instabiele training en beperkte controle over de uitvoer.
In 2015 werd het idee van diffusieprocessen geïntroduceerd, maar pas in 2020 werden ze praktisch toepasbaar met modellen zoals DDPM (Denoising Diffusion Probabilistic Models). Diffusion Models werken door een afbeelding stapsgewijs te verstoren met ruis en vervolgens te leren hoe deze ruis in omgekeerde richting kan worden verwijderd. Hierdoor kunnen ze van pure ruis realistische beelden genereren, zoals in DALL·E 2, Imagen en Stable Diffusion (2022-2023).
Door beelden na elkaar te generen op basis van de voorgaande kun je ook video’s maken! Door hieraan audio toe te voegen op basis van de getoonde beelden (via beeldherkenning weet je wat er getoond wordt) heb je ook nog eens geluid. En als mensen (of dieren) praten, lipsynchroon.
Verschillen tussen Language Models en Diffusion Models
Language Models genereren en begrijpen tekst, terwijl Diffusion Models beelden (en soms video’s of audio) produceren.
- Werking: Language Models werken met sequentiële voorspellingen (woord voor woord), terwijl Diffusion Models werken met ruisreductie door herhaalde bewerkingen.
- Training: LMs gebruiken enorme tekstdatasets en leren patronen in taal, terwijl DMs leren hoe ze structuren in afbeeldingen kunnen reconstrueren vanuit ruis.
- Toepassingen: LMs worden gebruikt in chatbots, vertalingen en documentanalyse; DMs in kunstgeneratie, fotorealisme en dataverbetering.
Beide technologieën zullen blijven evolueren en onze interactie met AI fundamenteel veranderen.
LLM – Large Language Models
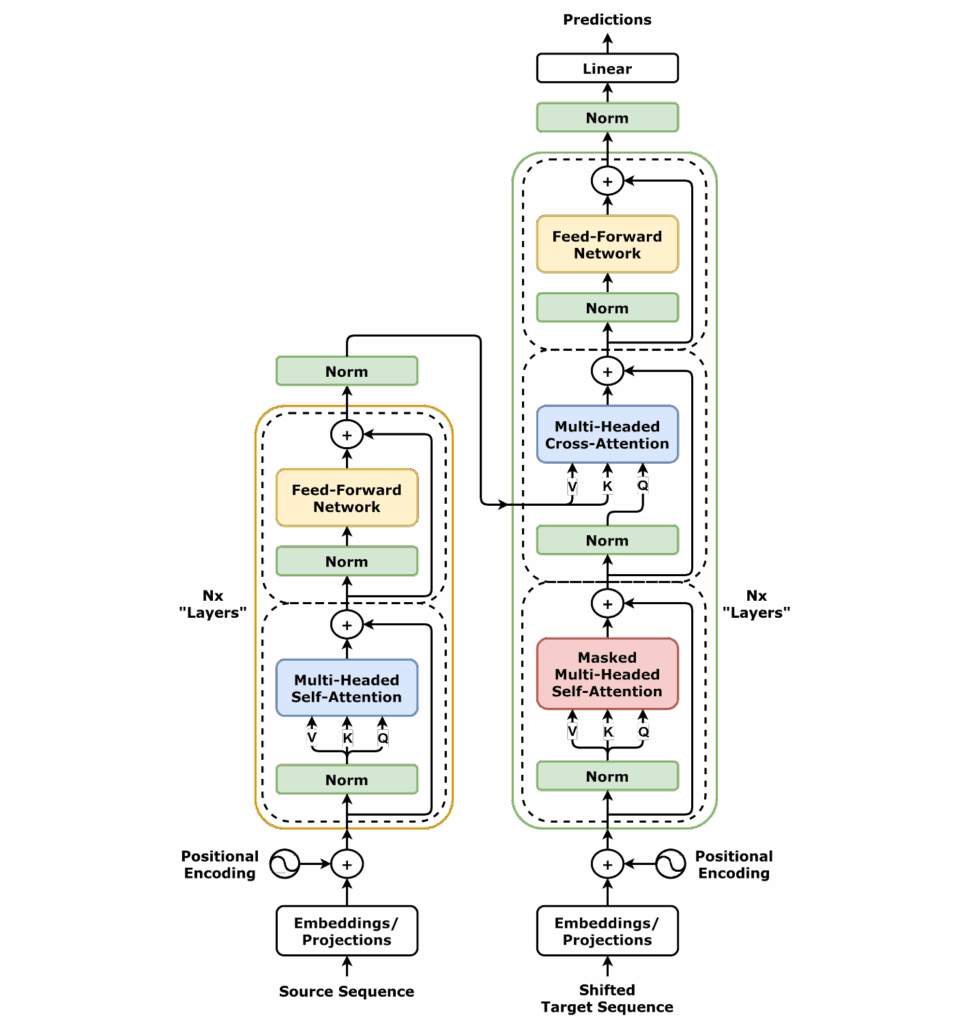
Van statistiek tot geavanceerde AI
Language Models (LMs) hebben een enorme evolutie doorgemaakt, van eenvoudige statistische technieken tot de krachtige AI-modellen van vandaag. Deze modellen vormen de kern van moderne taalverwerking en spelen een sleutelrol in chatbots, automatische vertalingen, zoekmachines en contentgeneratie.
Beginfase: Statistische modellen
De eerste taalmodellen waren gebaseerd op probabilistische statistiek. Het n-gram model, een van de vroegste methoden, voorspelde het volgende woord in een zin op basis van de frequentie van voorgaande woorden. Hoewel dit model effectief was in eenvoudige toepassingen, had het moeite met langere contexten en complexe grammaticale structuren.
Opkomst van Neurale netwerken en embeddings
De echte vooruitgang begon met neurale netwerken en de introductie van word embeddings. In de vroege jaren 2010 ontwikkelden onderzoekers modellen zoals Word2Vec (2013) en GloVe (2014). Deze technieken zetten woorden om in vectoren in een meer-dimensionale ruimte, waarbij woorden met een vergelijkbare betekenis dichter bij elkaar lagen. Dit verbeterde het begrip van context en semantiek aanzienlijk.
De Transformer Revolutie (2017)
De grootste doorbraak kwam in 2017 met de publicatie van “Attention is All You Need” door Vaswani et al. Dit introduceerde het Transformer-model, een architectuur die gebruikmaakt van zelf-attentie om woorden in een zin beter te begrijpen, ongeacht hun positie.
Deze innovatie leidde tot krachtige modellen zoals:
- BERT (2018): Begrijpelijke en contextgevoelige taalverwerking door bidirectionele analyse van tekst.
- GPT (2018-2023): Generatieve AI-modellen zoals GPT-3 en GPT-4, die vloeiende en coherente teksten kunnen produceren.
Werking van Moderne Language Models
Moderne LMs zijn gebaseerd op deep learning en worden getraind op miljarden woorden uit boeken, websites en andere tekstbronnen. Het belangrijkste mechanisme is:
- Tokenization: Tekst wordt opgesplitst in kleine eenheden (woorden of subwoorden).
- Embeddings: Elk token wordt omgezet in een numerieke vector.
- Attention Mechanisme: Het model analyseert hoe woorden zich tot elkaar verhouden.
- Voorspelling en Generatie: Op basis van getrainde patronen voorspelt het model het volgende woord of genereert het een volledig antwoord.
Toepassingen van Language Models
Momenteel worden LMs gebruikt in tal van toepassingen:
Chatbots & Virtuele Assistenten: ChatGPT, Google Bard en Alexa.
Automatische Vertalingen: Google Translate en DeepL.
Samenvattingen & Contentgeneratie: AI-gestuurde tekstschrijvers en journalistieke tools.
Codegeneratie: GitHub Copilot en OpenAI Codex voor programmeerhulp.
Toekomstperspectief
De ontwikkelingen gaan razendsnel. Multimodale AI (die naast tekst ook beelden en audio begrijpt), gepersonaliseerde LMs middels RAG en efficiëntere AI-modellen zullen de toekomst van taalverwerking verder vormgeven. Language Models blijven zich ontwikkelen en zullen steeds menselijker worden in hun interactie.
Diffusie Modellen
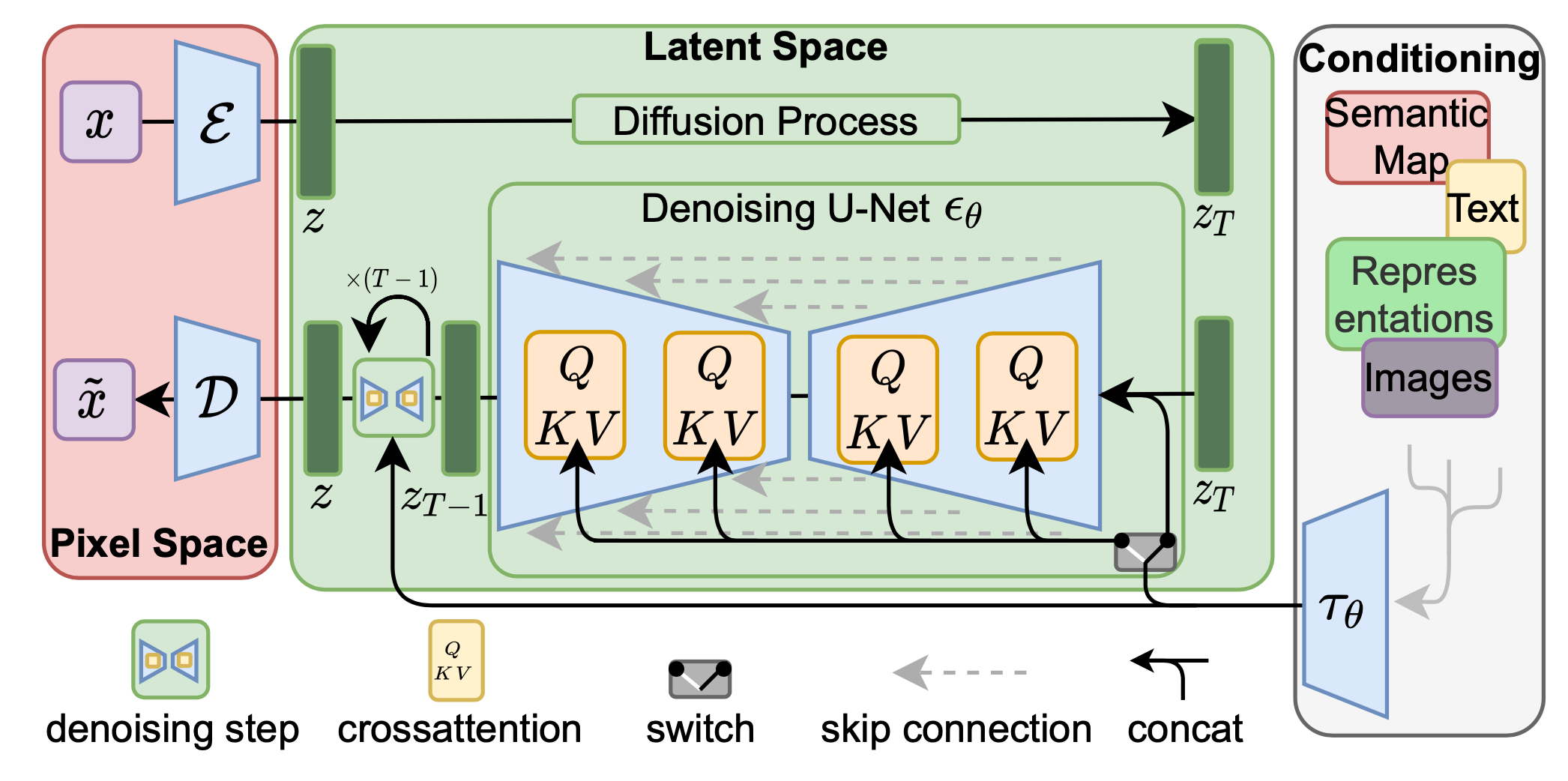
Bron: Rombach & Blattmann, et al. 2022
Creativiteit door ruis
Diffusie modellen zijn generatieve AI-modellen die uit een willekeurige plaatje met alleen maar ruis, geleidelijk de ruis verwijderen totdat de gewenste output, zoals een afbeelding, geluid of zelfs een 3D-model, tevoorschijn komt.
Hoe dat werkt?
Het basisidee is verrassend eenvoudig:
- Voorwaartse Diffusie: Een proces waarbij geleidelijk ruis wordt toegevoegd aan de trainingsdata totdat deze volledig willekeurig is.
- Omgekeerde Diffusie (Denoising): Het model leert vervolgens om dit ruisproces om te keren. Het wordt getraind om in kleine stappen de ruis te voorspellen en te verwijderen, waardoor de originele data langzaam weer ontstaat.
Door dit omgekeerde proces te herhalen, kan het model vanuit pure ruis nieuwe, realistische data genereren die lijkt op de data waarop het getraind is.
Waar ze voor worden gebruikt?
Diffusie modellen blinken uit in het genereren van gedetailleerde en diverse outputs, en worden steeds populairder in verschillende domeinen:
- Genereren van afbeeldingen: Denk aan tools die realistische afbeeldingen creëren op basis van tekstbeschrijvingen.
- Synthetische data: Het genereren van kunstmatige data voor trainingsdoeleinden, bijvoorbeeld in situaties waar echte data schaars is.
- Creatieve toepassingen: Het maken van unieke kunstwerken, stijloverdracht en het bewerken van bestaande media op innovatieve manieren.
Hoewel ze relatief nieuw zijn, laten diffusie modellen nu al indrukwekkende resultaten zien en beloven ze een belangrijke rol te spelen in de toekomst van AI-gestuurde creatie.
RAG – Retrieval-Augmented Generation
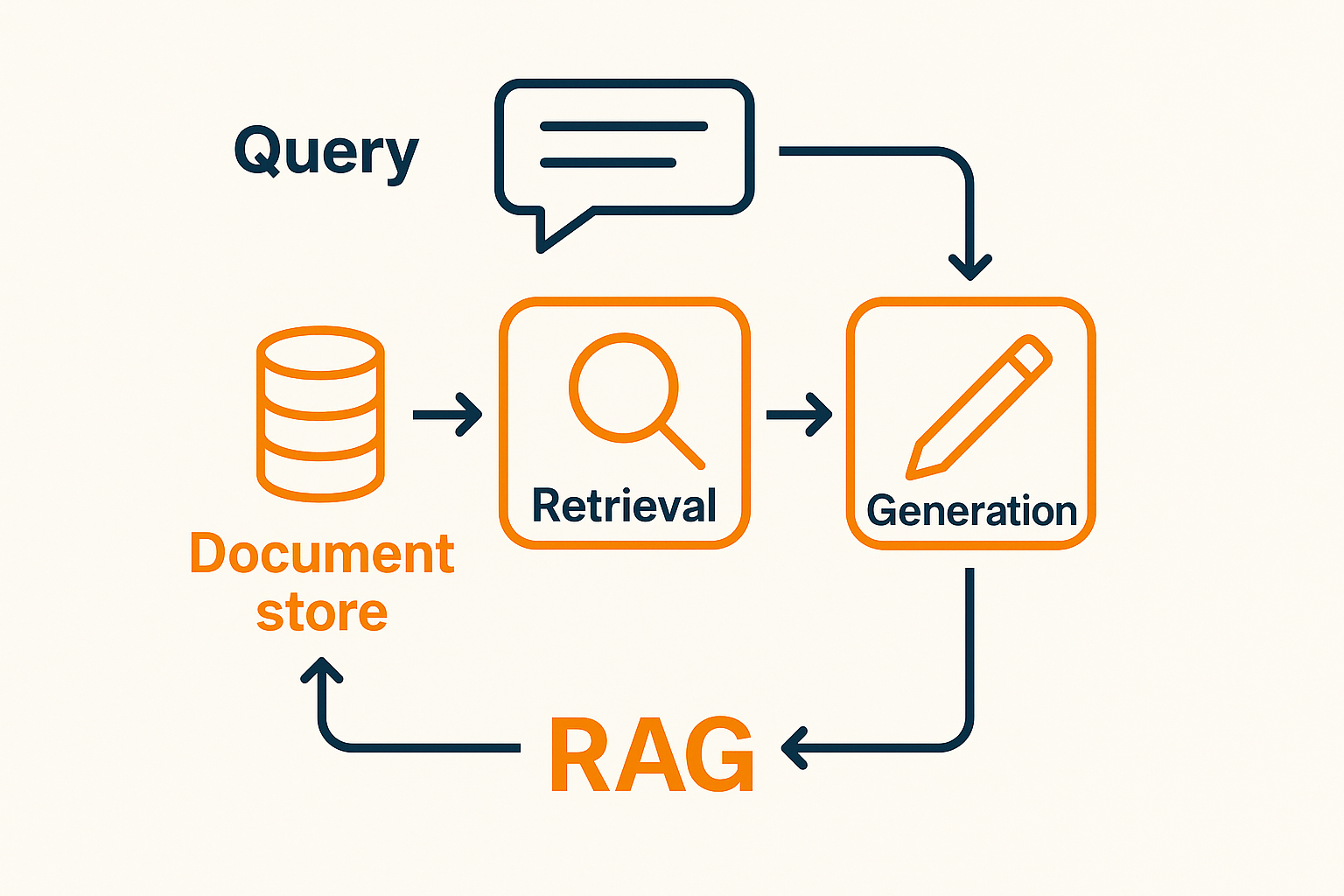
Retrieval-Augmented Generation (RAG) is een AI-techniek die taalmodellen verbetert door externe kennisopvraging te combineren met tekstgeneratie. In plaats van alleen te vertrouwen op vooraf getrainde kennis, haalt RAG dynamisch relevante informatie op uit een externe bron (bijv. een database, documentopslag of het web) en verwerkt deze in de respons.
Stappen in de RAG-Workflow
Gebruikersquery invoeren: De gebruiker stelt een vraag of geeft een prompt.
Embeddingmodel zet query om: De query wordt omgezet in een vectorrepresentatie (een numeriek formaat dat semantische betekenis vastlegt).
Opvragen uit kennisbank: Het systeem doorzoekt een vectordatabase (zoals FAISS, Pinecone of Weaviate) om de meest relevante documenten te vinden op basis van de embedding van de query.
Prompt aanvullen: De opgehaalde documenten worden toegevoegd aan de prompt die naar het taalmodel (LLM) wordt gestuurd.
Generatie door LLM: Het LLM verwerkt de uitgebreide prompt en genereert een antwoord met zowel de query als de opgehaalde kennis.
Embeddingmodel in RAG
Het embeddingmodel speelt een cruciale rol in het opvraagproces omdat het zowel de query als de documenten omzet in vector-embeddings binnen dezelfde semantische ruimte. Dit maakt efficiënte en betekenisvolle zoekopdrachten mogelijk.
Belangrijkste taken van het embeddingmodel:
– Zet tekst om in vector representaties: Legt betekenis vast die verder gaat dan exacte trefwoordovereenkomst.
– Maakt efficiënte semantische zoekopdrachten mogelijk: Vindt de meest relevante inhoud in een grote dataset.
– Verbetert contextuele relevantie: Zorgt ervoor dat de opgehaalde documenten goed aansluiten bij de intentie van de gebruiker.
Veelgebruikte embeddingmodellen zijn onder andere OpenAI’s text-embedding-modellen, Sentence Transformers (SBERT) en Google’s USE (Universal Sentence Encoder).
MCP – Model Context Protocol (tools)
Model Context Protocol (MCP) is een innovatieve technologie ontwikkeld door Anthropic’s Claude, ontworpen om AI-modellen beter contextueel begrip te geven en efficiënter met informatie om te gaan. MCP maakt het mogelijk om modellen op een slimmere en meer gerichte manier met lange-termijncontext te laten werken, waardoor AI nog beter aansluit bij zakelijke toepassingen.
Wat is MCP
MCP is een systeem dat AI helpt om grotere en persistente contexten te behouden zonder dat dit leidt tot overbelasting van het model. Normaal gesproken werken AI-modellen met een vaste contextlengte, wat betekent dat oudere informatie vaak “vergeten” wordt. MCP lost dit op door strategische contextbehoud en efficiënte verwerking van informatie, zodat modellen:
✔ Relevante informatie uit lange gesprekken behouden
✔ Beter inspelen op bedrijfsspecifieke kennis
✔ Efficiënter werken met complexe data zonder onnodige herhaling
Als bedrijfsassistent
Met MCP kan een AI-assistent een doorlopende context van klantvragen, documentatie en bedrijfsgegevens behouden, zonder telkens opnieuw getraind te worden. Dit betekent betere klantenservice, interne ondersteuning en snellere besluitvorming.
Efficiëntere automatisering
AI-modellen met MCP kunnen complexe workflows beheren, zoals:
- Contractanalyse in de juridische sector
- Supply chain optimalisatie in logistiek
- IT-support en debugging zonder verlies van historische gegevens
Verbeterde data-analyse en inzichten
Door contextuele data beter te beheren, kunnen bedrijven:
- Diepere inzichten halen uit klantinteracties
- AI gebruiken om lange rapportages of datasets te begrijpen
- Historische en real-time data combineren voor betere voorspellingen
Continue AI-learning in organisaties
MCP stelt AI in staat om lopende projecten en vergaderingen te onthouden en op te volgen, waardoor teams productiever worden zonder constant context te moeten herhalen.
Waarom is MCP een gamechanger
Langdurige contextbeheer: AI vergeet niet direct eerdere gesprekken of gegevens
Efficiënter gebruik van resources: Geen onnodige herhalingen, betere performance
Beter begrip van bedrijfsspecifieke informatie: AI past zich beter aan bedrijfsdoelen aan
MCP is dé sleutel voor bedrijven die AI niet alleen als een chatbot willen gebruiken, maar als een strategische en contextbewuste assistent.
A2A- Agent to Agent protocol
Agent2Agent is een manier om autonome agenten (met in de basis een LLM), te laten communiceren. In plaats van te vertrouwen op menselijke tussenkomst of gecentraliseerde systemen, kunnen agenten naadloos met elkaar samenwerken, informatie uit te wisselen en gezamenlijk complexe taken uit te voeren. Deze directe interactie opent nieuwe deuren voor efficiëntie, flexibiliteit en innovatie in diverse toepassingsgebieden.
Wat kun je er mee
Agent2Agent opent de mogelijkheid voor agenten om rechtstreeks te communiceren. Dit omvat het uitwisselen van data, het coördineren van acties, het onderhandelen over oplossingen en het gezamenlijk bereiken van doelen. In essentie creëert Agent2Agent een netwerk van intelligente entiteiten die in staat zijn tot gedistribueeerde probleemoplossing en samenwerking op een schaal en snelheid die voorheen niet mogelijk was. Door de barrières van indirecte communicatie te slechten, ontstaat een dynamisch ecosysteem van agenten die elkaar versterken in hun mogelijkheden.
Huh?
Je hebt dus slimme software-agenten die zelfstandig taken kunnen uitvoeren. Agent2Agent zorgt ervoor dat ze niet als losse eilandjes opereren, maar juist direct met elkaar kunnen overleggen en samenwerken. Zie het als een team van experts die constant met elkaar in contact staan om de beste resultaten te bereiken.
Het komt erop neer dat autonome software-agenten rechtstreeks met elkaar kunnen praten en acties kunnen ondernemen zonder dat er per se een mens tussen hoeft te zitten. Ze kunnen informatie delen, taken verdelen en samen tot oplossingen komen. Dit maakt alles een stuk sneller en flexibeler.
Een paar voorbeelden
Stel je voor dat je een webwinkel hebt met een agent die de voorraad beheert en een andere agent die de klantenservice doet. Met Agent2Agent kunnen die twee direct met elkaar communiceren.
- Voorbeeld 1: Voorraadtekort. De voorraadbeheer-agent merkt dat een bepaald product bijna op is door een onverwachte piek in bestellingen (geregistreerd door de klantenservice-agent). In plaats van dat de voorraadbeheer-agent dit pas later doorheeft of dat een mens moet ingrijpen, kan de klantenservice-agent direct een seintje geven: “Hey, die populaire gadget gaat hard, zorg dat er snel nieuwe komen!” De voorraadbeheer-agent kan dan automatisch een bestelling plaatsen bij de leverancier.
- Voorbeeld 2: Complexe klantvraag. Een klant heeft een ingewikkelde vraag die zowel productkennis als orderinformatie vereist. De eerste klantenservice-agent die de vraag ontvangt, kan via Agent2Agent direct een andere agent met meer productexpertise erbij “roepen”. Ze kunnen samen de vraag van de klant analyseren en een compleet en correct antwoord formuleren, zonder dat de klant lang hoeft te wachten of steeds naar iemand anders wordt doorgestuurd.
- Voorbeeld 3: Geautomatiseerde workflows. In een fabriek heb je misschien een agent die de status van machines monitort en een andere agent die de logistiek van onderdelen regelt. Als de monitor-agent een dreigend probleem met een machine detecteert, kan hij direct de logistiek-agent informeren: “Machine X dreigt uit te vallen, we hebben snel een nieuw onderdeel Y nodig.” De logistiek-agent kan dan automatisch de bestelling en het transport van dat onderdeel in gang zetten, waardoor kostbare downtime wordt voorkomen.
Door deze directe communicatie kunnen agenten dus veel sneller reageren op veranderingen, efficiënter samenwerken aan complexe taken en uiteindelijk betere resultaten leveren. Het is alsof je een goed geolied team hebt, waarbij iedereen perfect op elkaar is ingespeeld.
AP2- Agent Payment Protocol
Het Agent Payment Protocol (APP) is een door Google voorgestelde standaard waarmee autonome agenten niet alleen kunnen communiceren, maar ook zelfstandig betalingen kunnen uitvoeren en verifiëren. Waar Agent2Agent vooral gaat over samenwerking en informatie-uitwisseling, biedt APP de financiële laag die nodig is om transacties tussen agenten veilig, transparant en automatisch te laten verlopen.
Door APP krijgen agenten als het ware een eigen “digitale portemonnee” waarmee ze kosten kunnen afrekenen, inkomsten kunnen innen en onderling waarde kunnen uitwisselen – allemaal zonder menselijke tussenkomst of afhankelijkheid van een centrale partij.
Wat kun je ermee?
APP opent de deur naar volledig geautomatiseerde economische interacties tussen agenten. Dit betekent dat ze:
- Waarde kunnen overdragen – betalingen doen in crypto, tokens of digitale valuta.
- Diensten kunnen inkopen – bijvoorbeeld rekenkracht, data of API-toegang.
- Kosten kunnen verrekenen – automatisch bij gezamenlijke projecten of workflows.
- Transacties veilig afhandelen – met ingebouwde verificatie en fraudepreventie.
In essentie maakt APP het mogelijk dat agenten niet alleen samenwerken, maar ook zelfstandig economische relaties onderhouden.
Hoe dan?
Zie het zo: je hebt software-agenten die zelfstandig taken uitvoeren. Zonder APP zouden ze alleen informatie delen. Met APP kunnen ze ook écht betalen voor wat ze nodig hebben.
Dat werkt via een standaard protocol dat regelt hoe transacties worden gestart, gecontroleerd en afgerond. Hierbij spelen technologieën als blockchain, smart contracts en soms escrow-mechanismen een rol, zodat vertrouwen en veiligheid gewaarborgd zijn.
Het is alsof je een team van digitale collega’s hebt die niet alleen afspraken maken, maar ook meteen hun eigen facturen kunnen versturen en afrekenen.
Voorbeelden
1. Cloudservices inkopen
Een AI-agent die veel rekenkracht nodig heeft, schakelt een cloud-agent in. Zodra de taak klaar is, rekent hij automatisch af via APP. Geen mens hoeft contracten te tekenen of facturen te betalen – alles gebeurt direct tussen de agents.
2. Data-marktplaatsen
Een agent die marktanalyses maakt, koopt live-data in bij een data-provider-agent. Via APP betaalt hij per dataset of per query. Zo ontstaat een dynamische data-economie tussen agents.
3. Supply chain & logistiek
Een transport-agent levert goederen bij een magazijn-agent. Op het moment van aflevering wordt via APP direct de betaling uitgevoerd, bevestigd op de blockchain. Geen vertraging door factuurafhandeling, alles gaat instant en transparant.
4. Digitale samenwerking
Twee gespecialiseerde AI-agents werken samen aan een project: een vertaal-agent en een samenvattings-agent. Via APP wordt automatisch berekend wie hoeveel werk geleverd heeft en worden de opbrengsten eerlijk verdeeld.
Hoe werkt het technisch?
Het Agent Payment Protocol bouwt voort op bestaande financiële techniek:
- Blockchain: zorgt voor een gedeeld, onveranderlijk grootboek waarin betalingen transparant worden geregistreerd.
- Smart contracts: regelen automatisch de voorwaarden van transacties. Denk aan “Betaal alleen als de dienst correct geleverd is.”
- Escrow-mechanismen: houden tijdelijk geld vast totdat beide partijen bevestigen dat een taak goed is uitgevoerd.
- Digitale wallets voor agents: elke agent heeft een eigen wallet (bijvoorbeeld gebaseerd op cryptografie) waarmee hij kan betalen en ontvangen.
- Standaard API’s: definiëren hoe agenten betalingsverzoeken, bevestigingen en ontvangstbewijzen uitwisselen.
Door deze combinatie ontstaat een betrouwbaar systeem waarin agents elkaar kunnen vertrouwen zonder dat er een centrale bank of menselijke toezichthouder nodig is.
Kortom
Het Agent Payment Protocol tilt samenwerking tussen agenten naar een nieuw niveau. Ze kunnen niet alleen informatie delen en coördineren, maar ook zelfstandig waarde uitwisselen. Dit opent de weg naar een volledig geautomatiseerde digitale economie, waarin software-agenten diensten aanbieden, inkopen en afrekenen zonder menselijke tussenkomst.
Welke privacy
APP maakt van agents dus niet alleen slimme gesprekspartners, maar ook betrouwbare handelspartners. Althans dat is het idee. Want al je financiële informatie is dan wel in handen van een aanbieder als bijvoorbeeld Google. Dat is trouwens nu al het geval als je via je mobiel betaalt en bijvoorbeeld bij de Rabobank zit. Sommige banken hebben doodleuk het beheer van je financiële data aan Big Tech verkocht, zodat ze zelf niet meer de kosten van de app ontwikkeling hoeven te dragen. Big Tech had daar natuurlijk wel oren naar. Zo kunnen ze je nog beter volgen. Als je er niet voor betaalt, ben jij zelf het product! Follow the Money en je weet alles over iedereen.